
How to add partition to existing table in BigQuery?
Contents
Partitioned tables in BigQuery
Partitioned table is a special table that is divided into segments called partitions. Those partitioned tables are used to improve the query performance. Also it controls the costs by reducing the number of bytes read by query.
Different ways to partition the table
There are 3 ways to partition the table in BigQuery.
- Time-unit column: The columns TIMESTAMP, DATE, or DATETIME are considered as Time-unit. Based on this column, table can be partitioned in BigQuery.
- Ingestion time: The timestamp when the BigQuery ingests/consume the data is called as ingestion time. The table can be partitioned based on this ingestion time.
- Integer range: Any integer column can be used to define the partition in BigQuery.
Existing table in BigQuery
Consider that we have a table Transaction_history in BigQuery. It has columns Transaction_id, Amount, Transaction_type and Transaction_Date. Here the column Transaction_Date is in a DATE datatype. We will be adding this column as a partition to the table.
SELECT *
FROM rc_test_tables.Transaction_history;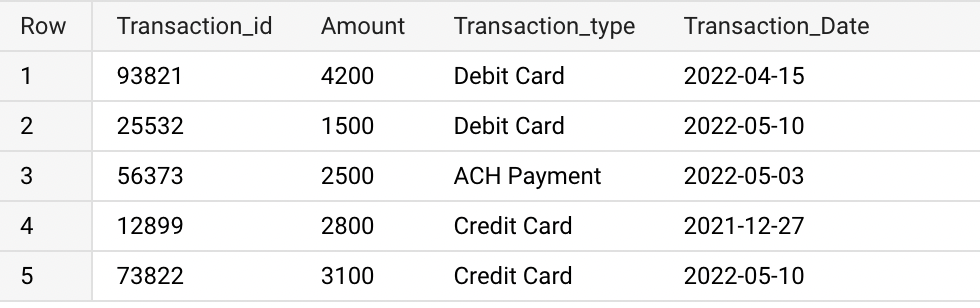
The table Transaction_history doesn’t have the partitions. We can confirm that by checking the table information in BigQuery web UI.
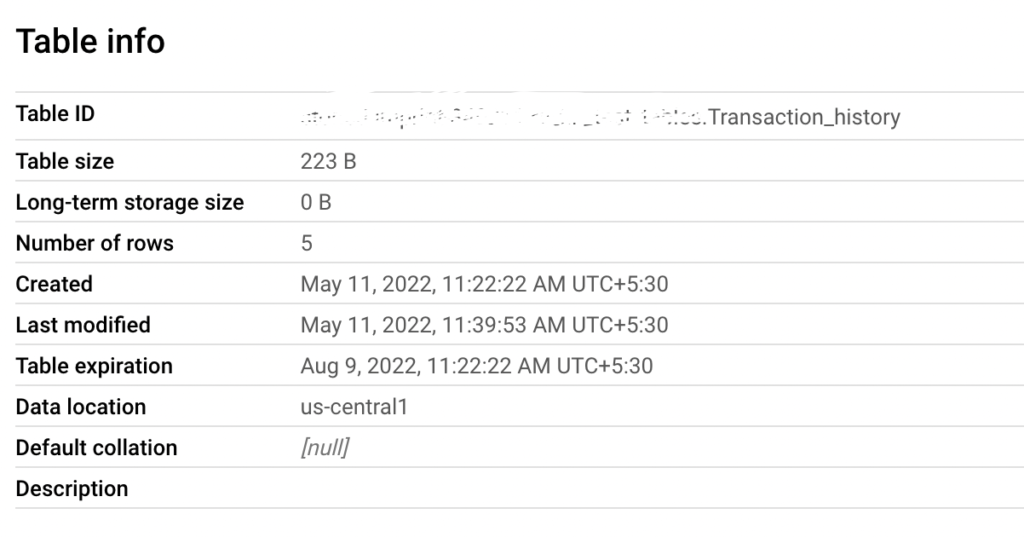
Also we can query the information schema as below to find the partition of the table. Since the partition_id is null, the Transaction_history table doesn’t have partitions.
SELECT * FROM `<Project_Id>.<Dataset>.INFORMATION_SCHEMA.PARTITIONS`
WHERE table_name = 'Transaction_history'
Add partition to existing table in BigQuery
BigQuery allows us to add partition to existing table using create table statement alone. Let’s use CREATE TABLE AS SELECT * statement to add the partition to existing table. This statement will create the new table with partition. Also it copy the data from old to new table. Here we are adding DATE column Transaction_Date as a partition.
CREATE TABLE rc_test_tables.Txn_history_partitioned
PARTITION BY Transaction_Date
AS
SELECT * FROM rc_test_tables.Transaction_history;After executing this statement, we can check the partition of the table from INFORMATION_SCHEMA.PARTITIONS.

As we shown above, the partitions are created for each transaction date. But we created the new table Txn_history_partitioned from existing table Transaction_history. Let’s perform the below steps to drop the old table and rename the new table.
DROP TABLE rc_test_tables.Transaction_history;
ALTER TABLE rc_test_tables.Txn_history_partitioned
RENAME TO Transaction_history;After executing the Drop and Alter statement, we can check the partitions of the table Transaction_history. The below image shows that it has the 4 partitions with date values.
SELECT * FROM `<Project_Id>.<Dataset>.INFORMATION_SCHEMA.PARTITIONS`
WHERE table_name = 'Transaction_history'
Next step is to verify the records from the table Transaction_history. To do that, We are running the Select query on this table. As we shown below, it has all the records.
SELECT * FROM rc_test_tables.Transaction_history;
Let’s check the table info of this table from BigQuery web UI also.
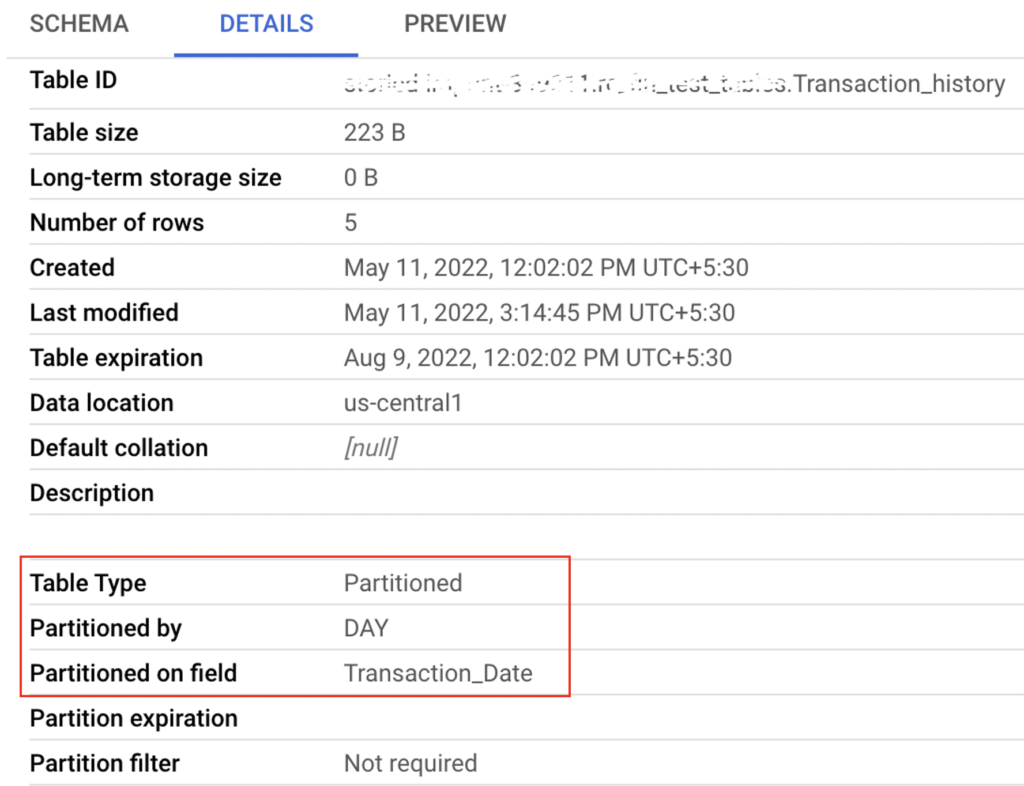
Finally the table Transaction_history has the partition of Transaction_Date. If we try to fetch the records based on Transaction_Date, BigQuery will scan only those particular partitions. To confirm this, we are running the below Select query with filter of Transaction date.
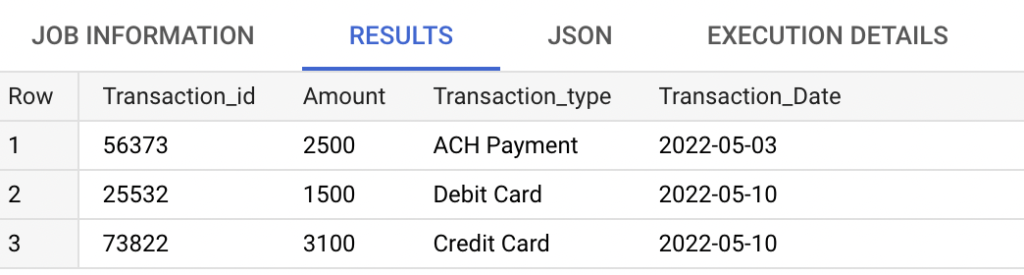
SELECT * FROM rc_test_tables.Transaction_history
WHERE Transaction_Date between '2022-05-01'
and CURRENT_DATE;As we expected, the query has processed only the partitions ‘2022-05-03‘ and ‘2022-05-10‘ and returned the below records.
Recommended Articles
- How to create an external table in BigQuery?
- How to create a view in BigQuery?
- Create table as Select, Create table Copy and Create table Like in BigQuery
Your Suggestions