
How to convert Pandas dataframe to Spark dataframe?
Contents
- 1 Convert Pandas to Spark dataframe
- 1.1 Syntax
- 1.2 Example 1: Convert Pandas to Spark dataframe using spark.createDataFrame() method
- 1.3 Example 2: Change column name and data type while converting the dataframe
- 1.4 Example 3: Use Apache Arrow for converting pandas to spark dataframe
- 1.5 Example 4: Read from CSV file using Pandas on Spark dataframe
Convert Pandas to Spark dataframe
In some cases, we use Pandas library in Pyspark to perform the data analysis or transformation. But Pandas has few drawbacks as below
- It cannot make use of multiple machine. In other words, it doesn’t support distributed processing.
- The whole dataset needs to fits into the RAM of the driver/single machine.
On the other hand, Spark DataFrames are distributed across nodes of the Spark cluster. When the amount of data is large, it is better to convert the Pandas dataframe to Spark dataframe and do the complex transformation. Let’s look at the ways to make this conversion.
Syntax
|
1 |
spark.createDataframe(data, schema) |
- spark – It is a spark session object
- data – List of values on which dataframe is created
- schema – The structure/column names of the data set
Example 1: Convert Pandas to Spark dataframe using spark.createDataFrame() method
Let’s create Pandas dataframe in Pyspark.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
import pandas as pd from pyspark.sql import SparkSession #Create PySpark SparkSession spark = SparkSession.builder.master('local')\ .appName('convert-pandas-to-spark-df')\ .getOrCreate() data = [[2992,'Life Insurance'],[1919,'Dental Insurance'],[2904,'Vision Insurance']] # create pandas dataframe pandasDF = pd.DataFrame(data=data,columns=['Code','Product_Name']) print(pandasDF) |
Output

Now we have a Pandas dataframe in the variable pandasDF. We can pass this variable into the CreateDataFrame method. So that it will be converted to Spark dataframe.
|
1 2 3 4 |
# convert pandas dataframe to spark dataframe sparkDF = spark.createDataFrame(pandasDF) sparkDF.show() sparkDF.printSchema() |
Output

Example 2: Change column name and data type while converting the dataframe
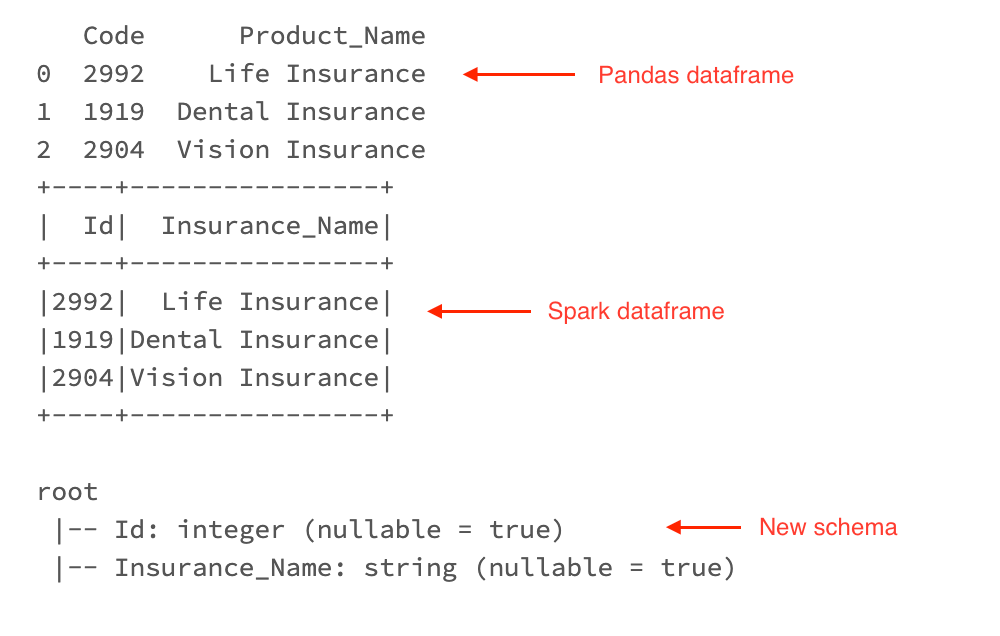
In this example, we use the same Pandas dataframe values. But we want to make the following changes in the Spark dataframe while converting.
- Change column name from “Code to Id” and “Product_Name to Insurance_Name“.
- Currently the column “Code” has the values in long data type. We want to change the data type to integer.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
import pandas as pd from pyspark.sql import SparkSession #Create PySpark SparkSession spark = SparkSession.builder.master('local')\ .appName('convert-pandas-to-spark-df')\ .getOrCreate() data = [[2992,'Life Insurance'],[1919,'Dental Insurance'],[2904,'Vision Insurance']] # create pandas dataframe pandasDF = pd.DataFrame(data=data,columns=['Code','Product_Name']) print(pandasDF) #Create new Schema using StructType mySchema = StructType([ StructField("Id", IntegerType(), True)\ ,StructField("Insurance_Name", StringType(), True)]) # convert pandas dataframe to spark dataframe with new schema sparkDF = spark.createDataFrame(pandasDF,schema=mySchema) sparkDF.show() sparkDF.printSchema() |
Output
As shown below, the column name and data type of the columns are changed in the Spark dataframe.
Example 3: Use Apache Arrow for converting pandas to spark dataframe
Apache Arrow is a cross-language development platform for in-memory analytics. It is an in-memory columnar data format that is used in Spark to efficiently transfer data between JVM and Python processes.
Let’s set this configuration in our Pyspark program. It can be used for dataframe conversion with larger dataset.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
import pandas as pd from pyspark.sql import SparkSession #Create PySpark SparkSession spark = SparkSession.builder.master('local')\ .appName('convert-pandas-to-spark-df')\ .getOrCreate() data = [[2992,'Life Insurance'],[1919,'Dental Insurance'],[2904,'Vision Insurance']] # create pandas dataframe pandasDF = pd.DataFrame(data=data,columns=['Code','Product_Name']) # Using arrow to convert pandas to spark spark.conf.set("spark.sql.execution.arrow.enabled","true") sparkDF=spark.createDataFrame(pandasDF) sparkDF.show() |
Output
As shown below, the Pandas dataframe is converted to Spark dataframe using Apache arrow.

Example 4: Read from CSV file using Pandas on Spark dataframe
In Spark 3.2, Pandas API is introduced with a feature of “Scalability beyond a single machine“. It is enabling users to work with large datasets by leveraging Spark.
Since it scales well to large clusters of nodes, we can work with pandas on spark without converting it to spark dataframe. To do so, we need to “import pyspark.pandas as ps” in our Pyspark program.
|
1 2 3 4 5 6 |
# read csv using pandas on Spark df import pyspark.pandas as ps df = ps.read_csv("/x/home/user_alex/student_marks.csv") #select records from pandas dataframe using spark ps.sql("select * from {df}") |
Output

Recommend Articles
References